
開発者が調査すべきソースコードの抽出
概要
ソフトウェアの大規模化に伴って,ソフトウェアの動作を正しく理解し,保守していくことが非常に困難となっています. ソフトウェアの欠陥の原因となるソースコードを特定,修正する場合には,開発者が1行ずつコードを読み進めていくことが効果的だと言われていますが,大規模なソフトウェアに対するそのような作業は,非現実的となっています.
このような問題に対して,肥後研究室では,開発者が注目すべきソースコードを自動的に抽出することで効率的なプログラム読解作業を可能とする方法を研究しています. このテーマに関する具体的な研究は大きく分けて2つあります.
- 1つは,開発者が注目しているコードと同じ機能に属する(何らかの関連を持っている)と推測されるコードだけを依存関係解析によって自動抽出する手法です.
- もう1つは,開発者が指定したコードと類似したコードを自然言語解析によって抽出する手法です.
これらの手法について,以下,それぞれ説明します.
依存関係解析を用いた機能抽出
依存関係解析とは,プログラムを解析し,制御やデータの依存関係(どのデータを使って新たなデータを計算したか)を取得する手法です. コンパイラなどがプログラムの性能を最適化するために使用している技術であり,また,プログラムのデバッグや保守においても有用であることが知られています.
例えば,図1のように,1行目で定義された a の値が3行目でcによって参照されている場合,1行目から3行目の文に対して依存関係が存在するといいます. 同様に2行目から3行目の文に対しても依存関係が存在します.

図2のように不正なデータが出力されているとき,依存関係を辿っていくことで,不正な処理が行われた可能性のある部分を探すことができます.
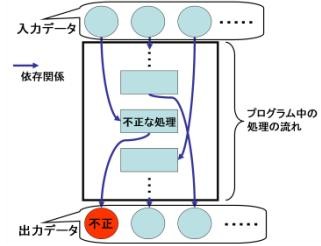
そして,図3のように,依存関係に従ってプログラムの一部だけを選択し,図4のように該当部分だけをソースコード上で強調表示することで,開発者が原因を特定する作業を支援することができます. このようにソースコードの一部を切り出す手法は,スライシングと呼ばれています.
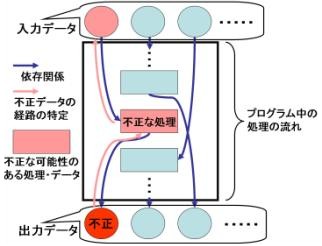
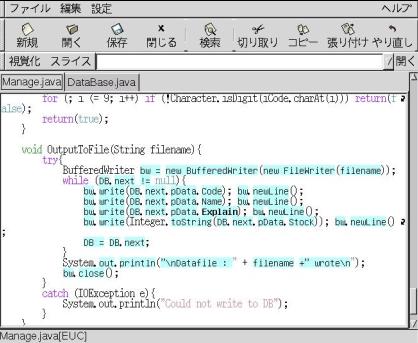
大規模なプログラムでは,依存関係が複雑になり,スライシングによって切り出されたソースコードですら,開発者が調査するには大きすぎるという状況が起こります. そこで,肥後研究室では,各メソッドの名前や,部品間の利用関係などから推測される機能上の関連の強さを用いて,開発者が注目している不正なデータの計算に強く関連していると推測される部品に対してのみ,スライシング計算を適用する手法を提案しています.
識別子解析を用いた類似コードの抽出
開発者は,あるコードを見本に新たなコードを記述した場合など,よく似たソースコードを複数回記述することがあります. そのため,たとえば欠陥の原因を取り除くなどの理由でソースコードを修正する場合に,他に類似したソースコードがないかを調べ,同様の修正を適用する必要がないか,検討することになります.
開発者はキーワード検索や,コードクローン情報などを頼りにして,他に類似したコードを書いていないか調査する必要があります. しかし,派生したコードの多くは,変数名などが目的に応じて変更されたり,追加のコードが挿入されていたりと,元のコードだけを手がかりに単純に検索しても発見することはできません.
肥後研究室では,自然言語解析における単語の「共起性」の概念を用いて,識別子が変更されたコードであっても検索可能とする手法を研究しています. 共起性とは,2つの単語が「同時に出現する」という性質であり,単語の関連性の強さを示すものです. 共起関係をすべての単語間で計算すると,たとえば「A は C,D,E と同時に出現することが多い」「B も C,D,E と同時に出現することが多い」ことから,「AとBは同義語であろう」という推測が可能となります.
共起関係を変数名,関数名に対して適用することで,たとえば,"add_host","add_node","alloc_host","alloc_node" というように名前が混在したプログラムでは,"host" と "node" には対応関係があると計算できます. すると,以下の図の左側にあるようなソースコードから図の右側にあるソースコードへ,対応関係を認識することができるようになります.
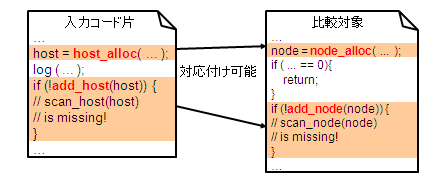
この対応関係の計算では,対応関係にある識別子同士が構文上,同じ種類(関数呼び出し,if文の条件式など)に属することを利用しています. 対応関係にある識別子の構文要素が変化しない限り,新しい行の挿入や,対応関係にない識別子の追加,削除などといった,変更には影響されないよう,工夫をしています.
この対応関係を用いると,開発者は,変更したいと思ったソースコードの範囲を選択するだけで,よく似たソースコード片を検索することができます. このようにして抽出された「同じだと思われるコード片」のリストを確認していくことで,開発者は,ソースコードの確認を効率よく進めていくことができます.
代表的な論文
- プログラムスライシングを用いた機能的関心 事の抽出(石尾 隆)
- 識別子の共起関係に基づく類似コード検索法の提案と欠陥検出への適用(服部 剛之)
- バイトコード間の動的依存情報を抽出するJavaバーチャルマシン(誉田 謙二)
- エイリアスフローグラフを用いたオブジェクト指向プログラムのエイリアス解析手法(大畑 文明)